摘要
激活图(Activation maps)已经被用来可视化深度学习模型,并且用来提升网络模型的性能。但是呢,网络模型又特别容易受对抗攻击的影响。虽然复原出分类器原本预测的结果是较难的,经常需要复杂的变换,但是呢,在对抗样本复原出原本的激活图是轻而易举的,既不需要修改分类器,也不需要对输入样本做出变化。
激活映射图
Activation Maps这个概念出自MIT周博磊发表于2016年CVPR上面的一篇论文[1]。
从自然图像中学到的卷积滤波器对于训练集中的1000个类别是敏感的,换句话说就是图像中包含相关类别的区域与卷积核进行卷积操作之后得到较高的激活值,而不包含类别的区域得到较小的激活值。Class Activation Maps(CAM)概念也就在此先验知识下应运而生,并且也验证了此想法。
Class Activation Maps的应用
物体定位的有效工具
提升图像分类网络
Visual question answering(VQA)
语义图像压缩
图像检索
注意网路(attention networks)[2]
对抗的影响
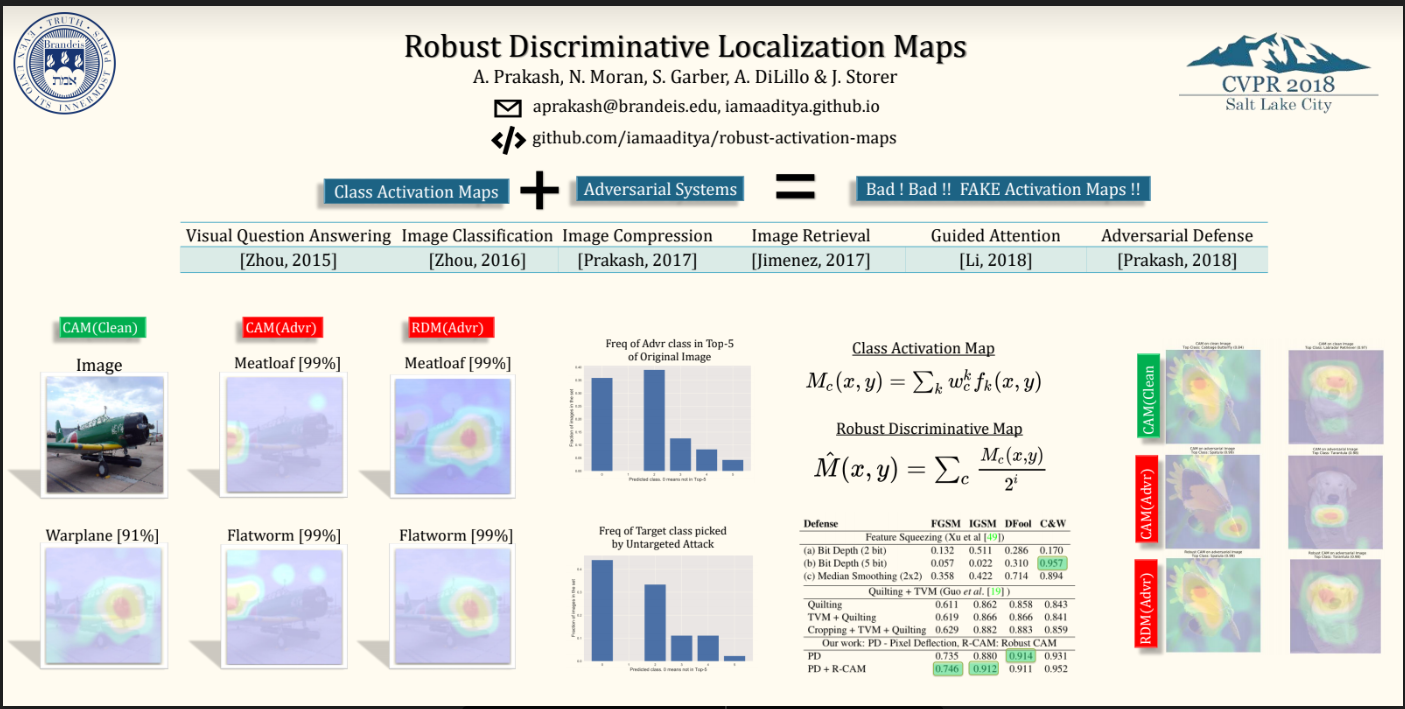
分类网络已证明容易被“愚弄”[3]、[4],例如白盒攻击(white-box attacks)。 因为对抗的影响,所以根据模型的预测结果即最高概率的类别也就是错误的,对应生成的激活映射图也就是错误的。如下图所示,左侧两张图代表的是由原始图像的预测结果得到的激活映射图,右侧两张图像代表的是由对抗样本图像的网络预测结果得到的激活映射图。可以发现得到的激活图是错的,这是为什么呢?原因就是网络的预测值(最高概率值所属的类别)在起着决定性作用。

Imagnet数据集的特性
ImageNet包含1000个类别。这1000个类别中的许多都是细粒度(fine-grained)。在Top-5中预测的类别中,第二个预测的类别很有可能与第一个类别是相近关系(作者原文提到说也有可能是synonym,但是我认为这是不对的,依据介绍数据集(ImageNet)的论文[5]3.1.1小节提到1000个synsets no overlap each other)。
方法
为了使激活映射图对于对抗样本也具有适应性,作者选取了的方法叫做前top-K的映射图指数加权求和(exponentially weighted average of the maps of the top-k classes)。
结果展示

最右侧是通过作者提出的方法的到的激活映射图,可以发现基本和最左侧得到的结果一致。
源码 code
疑惑
本文最大的困扰点是:作者通过实验证明对抗样本的预测类别与自然图像的预测类别关系介绍。

后记
这篇文章应该是站在别人经典工作的一小步探索,正验证了科研的一种方法。从施引文献中去发现可以改进的工作。
Poster
Reference:
- Learning deep features for discriminative localization
- Tell me where to look: Guided attention inference network
- Intriguing properties of neural networks
- Explaining and harnessing adversarial examples
- ImageNet Large Scale Visual Recognition Challenge
- Author Homepage:Aaditya Prakash (Adi)